


Information Theory: Obstacles To True Artificial Intelligence
With the Singularity Summit coming to San Francisco tomorrow, a lot of people are wondering about how close we are to successfully…

Information Theory: Obstacles To True Artificial Intelligence
With the Singularity Summit coming to San Francisco tomorrow, a lot of people are wondering about how close we are to successfully implementing Artificial Intelligence.
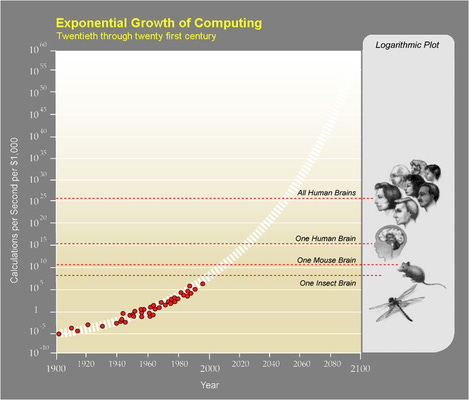
Probably you’ve seen a graph like the above before. Computers are getting faster. Does this mean we’re getting closer to true Artificial Intelligence? Not necessarily.
As I’ll show in the following paragraphs, both Artificial Intelligence and the less ambitious Machine Learning (ML) aren’t computationally but data bounded. This has profound implications for viable avenues for research and development.
Generally speaking, the goal of AI and ML research is to acquire a digitally executable copy of a model behavior. The specific model behavior desired can range from classifying (“are there humans in the picture?”, “ixs this news article about economics?”) to predicting values (“how much does a house in this neighborhood sell for?”), to making conversation like a human would (“a chatbot”).
Any such observable behavior can be mathematically described as a mapping from a set of finite input sequences to corresponding outputs, or in other words: a function. And any such function can be translated into a corresponding computer program.
That is, we can represent the model we want to learn (“respond to lines of chat messages like a human would” in the chat bot case) as a function, and then in turn said function as a computer program.
The length of the shortest computer program that provides a mapping equivalent to the model function, can be seen as a measure of the complexity of the model. (For example the shortest program that performs addition on input numbers obviously is shorter — that is, has lower complexity — than the shortest program that parses human acoustic speech)
Now, the goal of machine learning techniques often is seen as helping us acquire a computer program equivalent to the model we want to learn. In general, this feat is performed like this: A human writes a machine learning program L, which given training data T, generates desired program M.
The sleight of hand, in case you haven’t noticed, is that instead of writing M directly, the human has simply decided to write L which writes M for him. The problem is that if the shortest L is shorter than the shortest M, we’re inevitably missing information — there’s many many different candidate M we could be writing — but which one specifically are we supposed to write?
We need to acquire this information from somewhere, and the only place other than L we can get this information from is our training data T. T is a list of examples of M in action. This could be a data set of (houses, their location, and their sales price), or a list of pictures and whether they contain a human face, or log files of human chatroom conversation. The problem is that learning from examples without prior knowledge is notoriously difficult — to learn complex concepts we need an impractical amount of examples. (as proven in [1])
So let us recap here for a second: All the information that goes into producing M is a generator/machine learning function L (written by a human), and training data T (acquired through interaction with humans). The information encoded in L combined with the information extracted from T needs to at least match or exceed the information encoded in M. The only reasonable way to extract information from T is to encode information about its underlying pattern in L. That is: All the work needs to be done by humans.
We face the following conundrum: To get a better model, we either need make the learning algorithm more complex/write more code (which is human work), or we need to gather more or better sample data (which requires human work as well). The complexity of the model M that we want to learn can’t be essentially reduced — it needs to be captured in a combination of program and training data.
Since these are information theoretical limitations, Moore’s law and faster computers do not help. Even a computationally unbounded supercomputer would not be able to break the laws of information theory. Attempts to reduce the necessary work essentially by sophisticated machine learning methods can be compared with attempting to build a perpetuum mobile.
So how do we improve computer models? More often than not the answer is through more and better data. Humans often have knowledge about underlying relationships between data, which helps them write better M and L. But for problems where they themselves haven’t understood the underlying relationships, they are no help. Since the contribution of machine learning techniques to knowledge acquisition tends asymptotically to zero from a viewpoint of algorithmic information theory, more or better data is needed.
Interestingly enough economists Mises and Hayek have discovered the necessity of data to decision making already in the 1920s in their treatises on the Economic Calculation Problem. Since markets force humans to interact, they reveal preferences through interaction. When removing the market, this preference data is never revealed. Thus the market is required to acquire the extract the data needed to do economic planning from people’s heads. In a similar fashion the problem of AI needs to be approached with additional data.
Either this data is directly extracted from a physical medium we know it to be encoded in (e.g. by scanning our body and brain), or we need to find ways to scale the amount of relevant data available to machine learning systems significantly.
A second way besides scanning would be simulation: If we’re fundamentally data limited, and we can’t acquire sufficient data from the physical world through adding sensors or collecting data, maybe we can make computers collect data from world’s of their own creation. In the simple case this would amount to computers playing games of parametrizable difficulty similar to Chess or Go against each other. It’s far easier to specify a game like Go than it is to fully understand it — so in theory we can let the computers explore a search space that provides its own data. The problem is that exploration of such a kind might over time approximate the complexity of a full particle simulation. It’s not clear how deep we’d have to search to find the kind of consciousness patterns we’re looking for. But we need to keep in mind that we might need to simulate an entire universe to find the patterns we are looking for.
Embodiment is the remaining third way, and one that had been chosen for humanity long before it made its own decisions. Here new bodies come loaded with both sensors and computational power. Since structurally there’s no clear boundary between the processes of cognition and living, this could be considered part of an efficient search process for consciousness throughout the entire universe. In this argument, our physical embodiment is actually a fairly efficient vessel, and humanity is more likely than not to become a first super-intelligence. The internet then amounts to said super-intelligence performing brain-surgery on itself, because changing the plumbing makes it capable of acting in a smarter more coordinated fashion, and those of us who develop better information routing technology simply continue the procedure.
In Summary: The real problem of creating good AI is data and complexity, not computational power. The information theoretical bounds described above apply equally to computers of finite and infinite computational power.
In essence, an equivalent question to “can we learn intelligence by observing intelligent behavior” is: Can we learn about the structure of living organisms simply by looking at recorded DNA data. If so, how many DNA samples do we need? A lot. If we could examine the physical organism directly instead, we’d learn a lot faster.
It’ll be interesting to see where all this goes.
Post-Script: I’ve omitted formality in my arguments for the sake of reaching an audience. For a formal argument please see A. Hoffmann, ECAI 1990 and A. Hoffmann, Minds & Machines 2010, whom I’ve often simply paraphrased and in two cases quoted verbatim.